How special is your server?
Them: “Dude, we can’t do anything.”
Me: “Yeah, I know. I told you this would happen. You can’t skip database maintenance.”
Them: “Dude, we can’t do anything.”
Me: “Yeah, I know. I told you this would happen. You can’t skip database maintenance.”

From my many years in the field, many interviews conducted, many tragedies experienced and averted, many hours spent in extra-vocational activities, I can absolutely distill everything I want you to know down to one simple thing: Test your knowledge.

I’ve often seen a company stuck with an old product version 10 or 20 years because the upgrade would be too onerous. Here are some basic tips to make the process easier. I’m going to concentrate on SQL Server upgrades, but many of these apply to most any product.
We spend a lot of time thinking about the problems and solutions for shops with dozens or 100s of SQL instances. So, here’s a “choose your own data adventure” for you, large-SQL-shop-person!
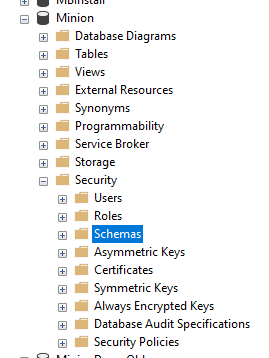
Today we’re going to hit my top 5 – well, top 6 – boots-on-the-ground security tips for SQL server: schemas, db_owner, dynamic SQL, DENY, crossover groups, and secondary servers.

There’s quite a bit of overlap among HA technologies, but they’re typically meant to protect against different things. The good news: many of them work together quite well! Here are the more popular approaches, and what they’re primarily for.

Data folks talk a lot about uptime and “five nines”…a goal which means that 99.999% of the time, the system must be up. The issue is that many companies don’t bother to define what downtime means to them, and what downtime-causing threats are.

Your SQL shop has, is, or will eventually need to consolidate many instances down to a few, or at least fewer. So what’s the best way to plan and execute a consolidation? Let’s lay out the steps.
Your SQL shop has, is, or will eventually need to consolidate many instances down to a few, or at least fewer. So what’s the best way to plan and execute a consolidation? Let’s lay out the steps.
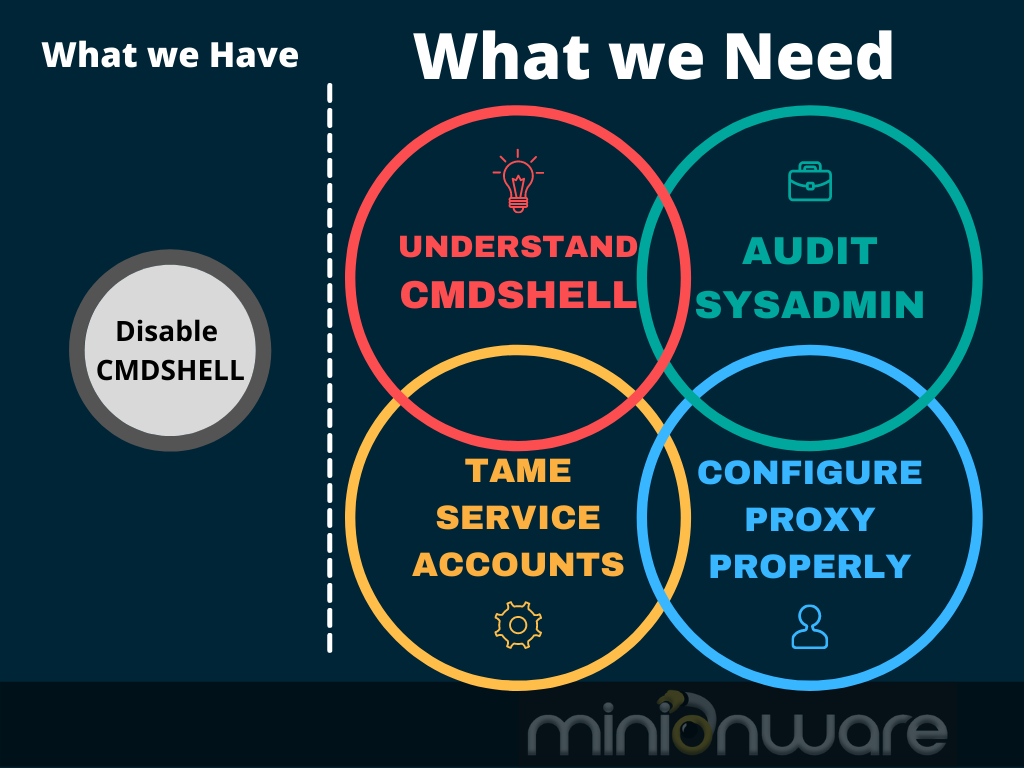
Quite a lot of data folks are reasonably concerned with the possible security holes that xp_cmdshell could introduce. Unfortunately, all the wrong things get all the attention. In this article, we cover what you really need to understand and secure xp_cmdshell, with a nice summary at the end.