SQL Server Security on the Ground
Today we’re going to hit my top 5 – well, top 6 – boots-on-the-ground security tips for SQL server: schemas, db_owner, dynamic SQL, DENY, crossover groups, and secondary servers.
Today we’re going to hit my top 5 – well, top 6 – boots-on-the-ground security tips for SQL server: schemas, db_owner, dynamic SQL, DENY, crossover groups, and secondary servers.
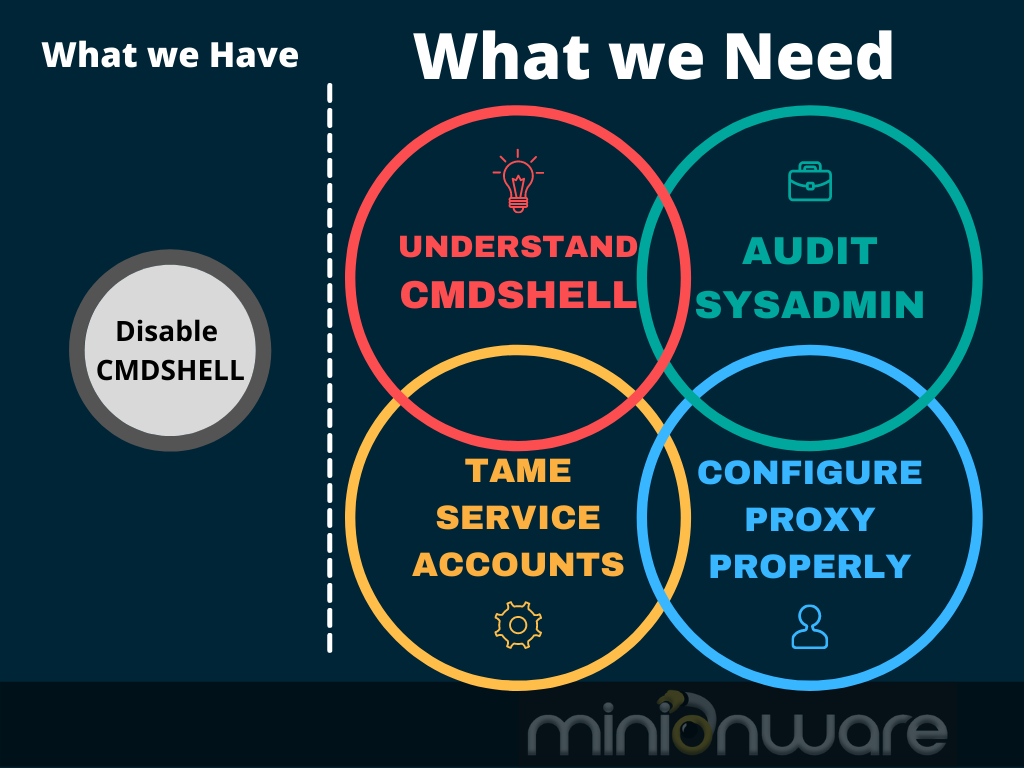
Quite a lot of data folks are reasonably concerned with the possible security holes that xp_cmdshell could introduce. Unfortunately, all the wrong things get all the attention. In this article, we cover what you really need to understand and secure xp_cmdshell, with a nice summary at the end.

Solutions to age-old problems are often very hard to see. It takes a new, visionary perspective to see the issue clearly and to find a solution that’s better, easier, and kinder. Learn the process of being a SQL visionary here!

There are daily reports of data leaks and ransomware attacks that maim companies in the public eye. What is it you’re supposed to do? Live in audit mode!

Ransomware is becoming a huge problem in the corporate world as more and more companies fall prey to this heinous act of terrorism. One of the biggest disasters that could befall you as a company – or even specifically as a DBA – is to come in one day and discover your shop has been …
Protect yourself from Ransomware with Minion Enterprise Read More »

As the new DBA, I’m here to fix things for you. I’m going to take care of the things that keep causing fires and outages and slowdowns….and I’m locking down your dev environment. Here’s why.
You’ve heard me talk about this many times, in so many different ways, but it’s worth repeating: SQL maintenance lifecycles are important.
People who disagree, disagree because they spend too much time firefighting and don’t have time to really think about it. Don’t know anything about SQL maintenance lifecycles? Let’s touch on a couple of points…today, we’ll cover SQL backup.
Every IT shop has its problems with performance: some localized, and some that span a server, or even multiple servers. Technologists tend to treat these problems as isolated incidents – solving one, then another, and then another. This happens especially when a problem is recurring but intermittent. When a slowdown or error happens every so often, it’s far too easy to lose the big picture.
Some shops suffer from these issues for years without ever getting to the bottom of it all. So, how can you determine what really causes performance problems?
What’s the most expensive cup of coffee you’ve ever bought? Was it $6, $8, $15? Try a cup of coffee that cost $2,000. And worst yet, it was made at home. Let me tell you a tale of disaster recovery…
The number one cause of instability in most database environments is SQL Server permissions. Specifically the problem is that people have more access to systems than they should. Let me walk you through a typical lockdown.